고정 헤더 영역
상세 컨텐츠
본문
불균형 데이터로 학습한 분류모델은 치우친 클래스에 대해 편향되는 문제가 발생한다.
클래스 불균형 비율이 9 이상이면 편향된 모델이 학습될 가능성이 크다. (그러나 항상 문제가 발생하는 것은 아니므로 클래스 불균형 비율만 보는것보다 k-최근접 이웃 모델처럼 클래스 불균형에 민감한 모델을 학습하여 성능을 확인하는 것이 좋다.)
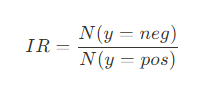
클래스의 분포를 균형있게 바꾸기 위해,
소수클래스 샘플을 생성하는 오버샘플링 혹은 다수클래스 샘플을 제거하는 언더샘플링으로 재샘플링한다.
1. 오버샘플링
- SMOTE 활용: KNN을 사용해 새로운 데이터를 생성하는 방법
from imblearn.over_sampling import SMOTE
smote = SMOTE()
s_X_train, s_y_train = smote.fit_resample(X_train, y_train)
- 랜덤 오버샘플링
ros = RandomOverSampler(random_state=50)
s_X_train, s_y_train = ros.fit_resample(X_train, y_train)
2. 언더샘플링
- 랜덤 언더샘플링
rus = RandomUnderSampler(random_state=50)
s_X_train, s_y_train = rus.fit_resample(X_train, y_train)
- NearMiss 활용: KNN을 기반으로 다수 클래스 샘플을 선택적으로 제거하는 방법
from imblearn.under_sampling import NearMiss
nm = NearMiss()
s_X_train, s_y_train = nm.fit_resample(X_train, y_train)
데이터가 적으면 오버샘플링이 유리하며, 데이터가 많으면 언더샘플링이 빠르고 효율적이다.
가장 좋은 방법은 SMOTE(소수 클래스 증강) + 랜덤언더샘플링(다수 클래스 조정)으로 함께 사용하는 것이다.
재샘플링 외에는 비용민감모델(거짓부정에 더 큰 가중치를 부여한 손실함수 사용)을 활용하는 해결방법이 있다.
참고 서적 : GIL's LAB, 「파이썬을 활용한 머신러닝 자동화 시스템 구축」, 위키북스(2022)
'테크 > ML' 카테고리의 다른 글
| [ML] 사이킷런 지도 학습 클래스 정리 (0) | 2025.02.12 |
|---|---|
| [ML/python] 필터링 기반 특징 선택 (Feature selection, Filter Method, SelectKBest) (0) | 2025.02.10 |
| [ML/python] 스케일링 (정규화, 표준화, Normalization, Min-Max Scaling, Standardization, Z-score Scaling) (0) | 2025.02.09 |
| [ML/python] 범주형, 서열형 변수 처리 (더미화, 치환) (0) | 2025.02.09 |
| [ML/python] 결측값 처리 (SimpleImputer, KNNImputer) (0) | 2025.02.09 |




