고정 헤더 영역

상세 컨텐츠
본문
2022년 7월 진행한 롯데멤버스 빅데이터 경진대회 기록입니다.
목차
1. 세그먼트와 개인화의 중요성
1-1. EDA
2. 고객 군집화 사용 변수
2-1. 변수 생성:제휴사 이용성향
2-2. 변수 생성:일주일 이용패턴
2-3. 변수 생성:상품취향(RC1~6)
3. 고객 군집화
3-1. 군집화 결과 및 마케팅전략
4. 군집 내 추천시스템
4-1. ALS추천시스템 선정이유
4-2. 추천시스템 적용
4-3. 모델 성능 평가 및 기대효과
1. 세그먼트와 개인화의 중요성
디지털 퍼스트 시대에서 대부분의 소비자는 고객경험이 제품만큼 중요하다고 생각한다.
또한 개인화된 경험을 기대하는 고객이 점점 늘어나고 있다. 기업 입장에서도 고객들을 세분화해 그룹으로 묶는다면, 한 명 또는 전체로서의 고객일 때 보다 마케팅 등에 있어 비용 대비 좋은 효과를 얻을 수 있으며, 로열티 높은 고객을 얻을 수 있다.
따라서 효율적인 고객관리가 가능하도록 고객을 세분화시켜 특성을 가진 세그먼트를 생성했다.
- 데이터 선택 및 전처리
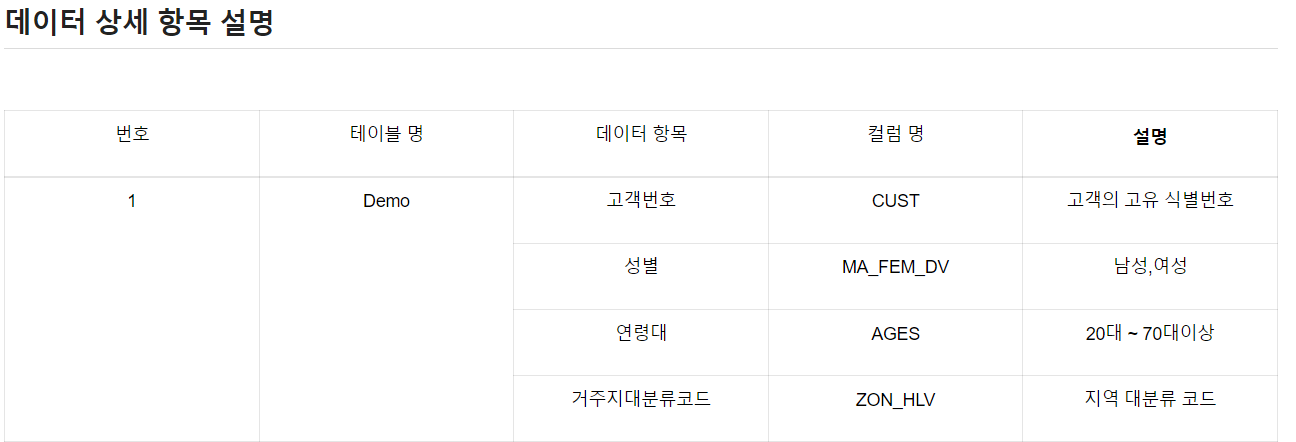




SQL로 상품구매정보(pdde) 테이블에 고객정보(demo)와 상품정보(pd_clac)를 포함한 pdde_merge 데이터를 만들었다.
select pdde.*, demo.ma_fem_dv, demo.ages, demo.zon_hlv as demo_zon_hlv, pd_clac.pd_nm, pd_clac.clac_hlv_nm, pd_clac.clac_mcls_nm
from pdde
left outer join demo
on pdde.cust = demo.cust
left outer join pd_clac
on pdde.pd_c = pd_clac.pd_c
제휴사 이용정보(cop_u)에 고객정보(demo)와 점포정보(br)를 포함한 cop_u_merge 데이터를 만들었다.
select cop_u.*, demo.ma_fem_dv, demo.ages, demo.zon_hlv as demo_zon_hlv, br.cop_c, br.zon_hlv as br_zon_hlv, br.zon_mcls
from cop_u
left outer join demo
on cop_u.cust = demo.cust
left outer join br
on cop_u.br_c = br.br_c
- 상품구매정보 EDA

이용자 중 여성의 비율이 70% 정도. 40대 이용자 비율이 가장 높다.

금,토,일에 구매가 많이 발생하고, 제휴사 A01, A02에서의 구매가 전체 구매의 70%가량을 차지한다.

총 이용횟수와 총 이용금액의 그래프. 각 변수는 아래 R코드를 통해 생성했다.
#rct_pdde : pdde영수증(제휴사, 이용액, 고객, 날짜)
rct_pdde <- unique(pdde %>%
group_by(rct_no) %>%
summarise(cop_c = cop_c, rct_am=sum(buy_am), cust = cust, de_dt = de_dt))
# pdde 영수증, 이용액
tmp <- rct_pdde %>%
group_by(cust)%>%
summarise(pdde_rct_cnt = n(), pdde_sum = sum(rct_am))
demo <- merge(x = demo,y = tmp,by="cust", all.x = TRUE)
# copu 영수증, 이용액
tmp <- copu %>%
group_by(cust)%>%
summarise(copu_rct_cnt = n(), copu_sum = sum(buy_am))
demo <- merge(x = demo, y = tmp,by="cust", all.x = TRUE)
# 두 영수증과 이용액 더하기
demo$rct <- apply(demo[,c("pdde_rct_cnt","copu_rct_cnt")],1,sum)
demo$am <- apply(demo[,c("pdde_sum","copu_sum")],1,sum)
여러 변수들에서 차이를 보이기에 고객 세분화가 가능할 것으로 보인다.
2. 고객 군집화 사용 변수

고객 분류에 유의미한 변수를 선정했다.
성별, 나이, 총 이용 횟수, 총 지불금액은 제공되거나 이미 만들어 둔 변수이고,
제휴사 이용성향, 이용패턴(일주일), 상품취향(유통) 변수는 새롭게 생성할 필요가 있다.
1) 제휴사 이용성향
각 제휴사 이용 비율(각 제휴사 이용 횟수 / 총 이용 횟수) 을 이용해 k-means 클러스터링했다.
# 제휴사별 이용 비율
dat <- data.frame(dcast(rct_pdde,cust~cop_c))
demo <- merge(x = demo,y = dat,by="cust", all.x = TRUE)
dat2 <- data.frame(dcast(copu,cust~cop_c))
demo <- merge(x = demo,y = dat2,by="cust", all.x = TRUE)
demo[is.na(demo)] <- 0
sum(is.na(demo))
demo[,7:18] <- demo[,7:18]/demo$rct #제휴사별 영수증을 총 영수증개수로 나누기
# 제휴사 이용 성향(clus_cop) 생성
#elbow method
fviz_nbclust(demo[7:18], kmeans, method = "wss", k.max = 12) +
theme_minimal() +
ggtitle("Elbow Method")
#silhouette
kClusters <- 2:9
resultForEachK2 <- data.frame(k = kClusters, silAvg = rep(NA, length(kClusters)))
for(i in 1:length(kClusters)){
resultForEachK2$silAvg[i] <- avg_sil(kClusters[i], demo[7:18])
}
plot(resultForEachK2$k, resultForEachK2$silAvg,
type = "b", pch = 19, frame = FALSE,
xlab = "Number of clusters K",
ylab = "Average Silhouettes")
#6개군집 생성
clus_cop <- kmeans(demo[7:18],6)
table(clus_cop$cluster)
demo$clus_cop <- as.factor(clus_cop$cluster)
군집 수가 6개일 때 실루엣계수가 높고, 7개로 늘어날 때 elbow method 그래프에서 기울기가 완만해지므로
6개의 클러스터로 이루어진 변수를 생성했다.






- 제휴사 이용 성향(clus_cop) 변수 생성 결과
1그룹 : D01을 주로 이용함.
2그룹 : A03을 주로 이용하고, A01, D01도 이용하는 고객이 있는 편
3그룹 : 큰 경향을 보이지는 않으나 A01, A02, A06, C01을 이용하는 고객들이 있는 편
4그룹 : A01을 주로 이용함.
5그룹 : A02를 주로 이용함.
6그룹 : A04를 주로 이용함.
2) 이용패턴
요일별 이용 비율(각 요일 이용 횟수 / 총 이용 횟수)을 이용해 k-means 클러스터링.
# 요일별 이용 비율
rct_pdde$wday <- as.factor(wday(ymd(rct_pdde$de_dt)))
str(rct_pdde)
dat <- data.frame(dcast(rct_pdde,cust~wday))
str(dat)
copu$wday <- as.factor(wday(ymd(copu$de_dt)))
dat2 <- data.frame(dcast(copu,cust~wday))
str(dat2)
names(dat) <- c("cust","sun","mon","tue","wed","thr","fri","sat")
demo <- merge(x = demo,y = dat,by="cust", all.x = TRUE)
demo <- merge(x = demo,y = dat2,by="cust", all.x = TRUE)
str(demo)
demo[is.na(demo)] <- 0
head(demo)
demo$sun <- apply(demo[,c("sun","X1")],1,sum) #pdde와 copu 합하기
demo$mon <- apply(demo[,c("mon","X2")],1,sum)
demo$tue <- apply(demo[,c("tue","X3")],1,sum)
demo$wed <- apply(demo[,c("wed","X4")],1,sum)
demo$thr <- apply(demo[,c("thr","X5")],1,sum)
demo$fri <- apply(demo[,c("fri","X6")],1,sum)
demo$sat <- apply(demo[,c("sat","X7")],1,sum)
demo <- demo[,c(1:27)]
# 요일별 영수증을 총 영수증으로 나누기
demo$sun <- demo$sun/demo$rct
demo$mon <- demo$mon/demo$rct
demo$tue <- demo$tue/demo$rct
demo$wed <- demo$wed/demo$rct
demo$thr <- demo$thr/demo$rct
demo$fri <- demo$fri/demo$rct
demo$sat <- demo$sat/demo$rct
# 요일별 패턴(pat2) 생성
training.data <- demo[demo$rct!=1,c(19:25)]
str(training.data)
#elbow method
install.packages("factoextra")
library(factoextra)
fviz_nbclust(training.data, kmeans, method = "wss", k.max = 9) +
theme_minimal() +
ggtitle("Elbow Method")
#silhouette
kClusters <- 2:9
resultForEachK2 <- data.frame(k = kClusters, silAvg = rep(NA, length(kClusters)))
#전체 실루엣 계수 평균 결과 계산
for(i in 1:length(kClusters)){
resultForEachK2$silAvg[i] <- avg_sil(kClusters[i], training.data)
}
#실루엣계수 그래프
plot(resultForEachK2$k, resultForEachK2$silAvg,
type = "b", pch = 19, frame = FALSE,
xlab = "Number of clusters K",
ylab = "Average Silhouettes")
wday_km <- kmeans(training.data,5)
demo$pat2[demo$rct!=1] <- as.factor(wday_km$cluster)

2개일 때 실루엣계수가 가장 높지만 세분화를 위해 5개의 클러스터로 이루어진 변수를 생성했다.



- 일주일 이용패턴(pat2) 변수 생성 결과
1그룹 : 주로 수요일에 이용.
2그룹 : 토>일.토요일에 가장 많이 이용. 주중보다는 주말 이용이 많은 편.
3그룹 : 주중에 주로 이용. 주중에서는 수요일이 낮은 편.
4그룹 : 금, 토, 일에 주로 이용. 토요일이 가장 높음.
5그룹 : 일>토. 일요일에 주로 이용. 주중보다는 주말 이용이 많은 편.
3) 상품 취향
구매한 상품의 대분류를 이용해 상품 취향을 파악했다.

총 대분류의 개수는 60개. 이 중에서 취향파악에 도움이 되지 않는 대분류는 제외하도록 했다.
먼저 각 고객이 대분류마다 구입한 횟수를 알 수 있는 데이터프레임을 생성하고, 각 대분류의 분산과 상관계수를 확인했다.
# 상품취향 파생변수(RC1~6) 생성 ---------------------------------
#고객X대분류 데이터프레임 생성
hlv <- dcast(pdde,cust~clac_hlv_nm,sum,value.var="buy_ct")
new_hlv <- hlv #잠깐 복사
new_hlv <- new_hlv[-c(1567,23258),] #이상치 제거
new_hlv <- new_hlv[,-1]
#대분류변수 선택
library(caret)
names(new_hlv[,nearZeroVar(new_hlv)]) # 0에 가까운 분산
new_hlv <- new_hlv[, -nearZeroVar(new_hlv)] #제거
findCorrelation(cor(new_hlv),cutoff = 0.4) # 상관계수 0.4이상
cor(new_hlv)[c(10,11,33,30,5,6,35,3,15,27),c(10,11,33,30,5,6,35,3,15,27)] #0.4이상
new_hlv <- new_hlv[,-c(11,33,30,5,6,35,3,15,27)] #10 두고 나머지 제거분산이 0에 가까운 대분류를 제외하고, 상관계수가 높은 대분류는 하나만 남겨두고 제외했다.
2023.3.13 셀프 리뷰
- 상관계수가 높은 변수들을 제거하지 않고 FA를 진행했다면 더 해석하기 쉬운 결과가 나왔을 것이다.
- 요인 추출 전, scale을 통해 분산을 1으로 만들어야한다.
- KMO, Bartlett을 통해 FA가 적합한지 확인한 후에 진행하는 것이 좋다.
- KMO(Kaiser-Meyer-Olkin factor adequacy) : 변수들이 상관을 갖는 정도로, 1에 가까울수록 요인분석을 하는 것이 적합한 변수라는 것을 의미하며, 0.5 이하는 요인분석을 하기에 부적합한 것으로 주로 여겨짐.
- Bartlett : 모든 상관관계가 0이라는 귀무가설을 세워놓고 이를 검정. 카이제곱과 p값을 보고 판단한다. p값이 유의한 수준(< 0.05)이면 만족한다. 카이제곱은 표본 크기에 민감하기에 주의.
new_hlv <- scale(new_hlv) KMO(new_hlv) cortest.bartlett(new_hlv)
library(psych)
library(GPArotation)
hlv.factor <- principal(new_hlv, rotate='none')
names(hlv.factor)
hlv.factor$values
plot(hlv.factor$values, type="b")
고유값 eigenvalue : 각 요인이 설명하는 분산의 크기. 각 변수들이 해당 요인에 적재된 값을 제곱하여 모두 합한 값. 요인분석에서는 각 변수의 전체 분산을 1으로 본다. 고유값이 1보다 작으면 그 요인의 설명력은 변수 하나보다도 작음을 뜻하기 때문에 요인의 수를 정할 때 고유값을 기준으로 사용하기도 한다.
고유값이 1보다 큰 값이 6개이므로 6개 인자를 선택했다.
2023.3.13 셀프 리뷰
- 더 간단하게 취향을 나누고 싶다면, screeplot에서 기울기가 급속도로 줄어드는 3번째 인자까지로 결정할 수 있다.
해석의 편의를 위해 직교회전을 사용했다.
hlv.Varimax = principal(new_hlv, nfactors = 6, rotate="varimax")
hlv.Varimax
loadings(hlv.Varimax)
#RC1:살림력 RC2:패션관심도 RC3:취미의 행복기여도
#RC5:윤택한 삶 욕구 RC4:아이위한 소비 RC6:가족외식
2023.3.13 셀프 리뷰
FA가 아닌, principal 함수로 PCA를 했다. (거의 비슷한 방법으로 진행되기에 FA와 PCA를 섞어서 잘못된 방법으로 쓰는 경우가 많다고 함.)
FA와 PCA의 차이에 대해 더 공부해본 결과, 이 경우에서는 FA를 사용하는 것이 좋다.
지금 의도하는 것은 대분류 변수들을 축소해서 더 큰 대분류로 만드려는 것이 아니라
구매 취향이라는 새로운 변수를 만들고싶은 것이기 때문에,
각 요인에 상관관계가 존재한다는 것을 인정하고, 고유요인의 분산을 인정하고, 선정된 각 요인의 중요성이 다르지 않도록 하는 요인분석(FA)를 사용할 수 있다.
상관관계를 인정하므로 요인회전은 oblimin회전을 사용할 수 있다.#요인개수 정하기------------------ library(psych) eigen(cor(new_hlv)) #8개까지 # fac <- principal(new_hlv, rotation='none')#초기.method:principal # fac$values #같은결과 #d <- fac(new_hlv, rotation='none') #method:minimum residual. mle는 factor개수 지정 필요.. #d$values #8개까지 plot(fac$values, type="b")#3개까지 scree(cor(new_hlv, use = "pairwise.complete.obs"))#3개까지 #3개------------------- fac3<- factanal(new_hlv,rotation= 'varimax', # 회전방법 지정 # scores= 'regression', # 요인점수 계산 방법 지정 factors = 3) #method:mle #fa(new_hlv, nfactors= 3, rotate = "varimax") fac3 fac3$scores # 인자 득점 == 원 데이터 좌표 sort(fac3$uniquenesses) print(fac3$loadings, cut=.4, sort=T, digits = 3) #오블리민 fac3o<- factanal(new_hlv,rotation= 'oblimin', factors = 3) print(fac3o$loadings, cut=.4, sort=T, digits = 3) # 8개 ------------------------ fac8<- factanal(new_hlv,rotation= 'varimax', factors = 8) fac8 fac8$scores sort(fac8$uniquenesses) print(fac8$loadings, cut=.4, sort=T, digits = 3) #오블리민 fac8o<- factanal(new_hlv,rotation= 'oblimin', factors =8) print(fac8o$loadings, cut=.4, sort=T, digits = 8)
참고sort(hlv.Varimax$uniquenesses) #고유요인의 분산 = 1-공통요인의분산 print(hlv.Varimax$loadings, cut=.5, sort=T, digits = 3) #정렬

- loadings : 요인이 변수에 끼치는 공분산의 크기. 요인과 변수들 간의 상관계수. (±0.5정도가 유의)
- SS loadings(eigen value) : 인자 적재량(loadings)의 제곱합. 높을수록 변수간 유사성이 좋다.
- Proportion Var : 전체분산 중 각 주성분이 차지하는 분산의 비율을 의미.
- Cumulative Var : 추출된 주성분의 분산합. 이 데이터에서는 36.3%를 설명한다.
RC1부터 RC6까지의 해석은 아래와 같다.
RC 1 : 살림력
RC 2 : 패션관심도
RC 3 : 취미의 행복기여도
RC 4 : 아이위한 소비
RC 5 : 윤택한 삶에 대한 욕구
RC 6 : 외식, 임대
위 해석을 기반으로, score를 이용해 새로운 고객 취향 변수 6개를 생성했다.
2023.3.13 셀프 리뷰
상관계수가 높은 변수를 제거하지 않고, FA분석을 oblimin회전을 이용해 다시 진행해봤을 때,
[3요인 ]
요인1 : 식품 구매 타입
요인2 : 식재료 구매 타입
요인3 : 패션, 식기/조리기구 구매 타입
[8요인]
요인1 : 식재료 구매 타입
요인2 : 패션 구매 타입
요인3 : 자취 간편식(과자,대용식) 구매 타입
요인4 : 깔끔 선호(세제/위생, 퍼스널케어)
요인5 : 직장인용품(사무용품,공구)
요인6 : 청소용품 구매 타입
요인7 : 마실 것 선호
요인8 : 외식 선호
비교적 요인간 상관관계가 없어보이지 않는 결과로 바뀌었다.
3. 고객 군집화


12개 변수를 이용해 고객을 군집화 진행.
연속형과 범주형 변수가 함께 있는 자료의 클러스터링을 위해
K-Prototypes 이용.
고객을 6개 군집으로 세분화.
군집화 결과
- 1그룹

더보기
18명
여성 39%, 남성 61%
40대 67%, 30대 17%, 50대 11%
이용패턴 4: 67%, 5: 22%, 2: 11%
제휴사성향 4: 100%
이용횟수 평균 188회
이용금액 평균 3억 2천만원
패션관심도 평균 4.18 윤택한삶욕구 평균 0.06
외식,임대 1.7
40대 전후의 이용횟수가 많고 금액이 매우 높은 고객.
대부분 A01 제휴사를 이용하며 금,토,일, 그중 토요일에 가장 많이 이용함.
패션관심도가 매우 높고 외식도 종종 하는 편.
⇒ 1그룹은 큰 소비를 하는 규모가 작은 그룹.
A01제휴사에서 토요일에 40대 고객이 좋아하는 브랜드의 프로모션 행사에 초대하는 등의 개인마케팅을 한다면 구매를 유도해 매출을 더 높일 수 있음.
- 2그룹

더보기
6663명
여성 83%, 남성 18%
40대 50%, 30대 20%, 50대 15%
이용패턴 4: 71%, 3: 10%
제휴사성향 5: 46%, 2: 12%, 4: 12%, 3: 11%
이용횟수 평균 57회
이용금액 평균 220만원
살림력 평균 0.2
취미의 행복기여도 평균 0.19
40대 전후의 여성. A02를 꽤 자주 이용. 살림력과 취미의 행복기여도가 평균보다 살짝 높음. 금,토,일에 주로 이용하고 토요일에 가장 많이 이용.
⇒ 가장 규모가 큰 그룹. 주말에 장을 보는 가정.
A02제휴사에서 토요일에 살림과 관련된 상품의 마케팅 진행 시 높은 효과를 기대할 수 있음.
- 3그룹

더보기
4904명
여성 30%, 남성 70%
30대 53%, 20대 15%, 40대 14%
이용패턴 3: 49%, 4: 21%
제휴사성향 3: 39%, 6: 14%, 1: 14%
이용횟수 평균 43회
이용금액 평균 139만원
30대 전후의 남성. 주중 이용량이 많은 편. 특별히 자주 이용하는 제휴사 없음.
⇒ 이용 횟수가 가장 적음. 필요하다고 느낄 때만 이용하는 경향이 있어보임.
고객이 몰랐던 필요한 상품을 추천하며 이용을 유도하는 방법.
- 4그룹

더보기
107명
여성 69%, 남성 31%
40대 40%, 30대 27%, 50대 25%
이용패턴 4: 61%, 5: 14%
제휴사성향 4: 96%
이용횟수 평균 180회
이용금액 평균 1억원
패션관심도 평균 2.4
아이위한소비 평균 0.5
윤택한 삶 욕구 평균 2.5
외식,임대 평균 1.1
40대 전후의 이용금액이 높은 고객.
대부분 A01 제휴사를 이용하며 금,토,일, 그중 토요일에 가장 많이 이용함.
패션관심도와 윤택한 삶에 대한 욕구가 높음.
외식을 하며 아이가 있을 확률이 있음.
⇒ 패션관심도와 삶의 질에 대한 욕구가 높기 때문에 이것을 건드릴 수 있는
새로운 제품 추천이 효과가 있을 것으로 보임.
- 5그룹

더보기
647명
여성 72%, 남성 28%
40대 36%, 30대 28%, 50대 21%
이용패턴 4: 59%, 3: 19%
제휴사성향 4: 86%
이용횟수 평균 143회
이용금액 평균 3115만원
살림력 0.16
패션관심도 평균 1.4
아이위한소비 평균 0.4
윤택한 삶 욕구 평균 1.5
외식,임대 0.6
40대 전후의 여성 고객.
A01 제휴사를 많이 이용하며 금,토,일, 그중 토요일에 가장 많이 이용함.
살림력이 있고 패션관심도와 윤택한 삶에 대한 욕구가 높음.
외식을 종종 하며 아이가 있을 확률이 있음.
⇒ 5그룹에는 아이가 있는 3인 이상 가족을 타겟으로 한 마케팅 진행.
(A01 제휴사 내 식당의 금액 조건부 할인쿠폰 제공 등)
- 6그룹

더보기
5547명
여성 87%, 남성 13%
40대 47%, 30대 19%, 50대 17%
이용패턴 3: 52%, 4: 18%
제휴사성향 4: 66%
이용횟수 평균 71회
이용금액 평균 441만원
패션관심도 평균 0.2
아이위한소비 평균 0.08
윤택한 삶 욕구 평균 0.1
외식,임대 0.3
40대 전후의 여성 고객.
다양한 제휴사를 이용하며 그 중에서는 A01 제휴사를 많이 이용.
주중에 이용량이 있는 편.
패션관심도와 윤택한 삶에 대한 욕구가 평균보다 높음.
가족 외식을 가끔 하는 편이며 아이가 있을 확률이 있음.
⇒ 이용 횟수에 비해 이용 금액이 낮다. 만족스러운 제품을 찾지 못했을 가능성이 있으므로 상품추천과 함께 할인쿠폰을 발행한다.
4. 군집 내 추천시스템
커다란 군집의 고객이 모두 같은 상품을 구매하는 것을 기대하기는 어렵다.
현명한 소비를 하는 고객이 많아졌고 개인마다 취향이 다르기 때문에, 비슷한 특성을 가진 그룹안에서도 상품을 보는 관점이 다를 수 있다. 따라서 군집이 아닌 개인에 대한 상품 추천이 필요하다.
또한 고객의 입장에서는 번거롭게 상품을 비교하는 과정 없이 만족스러운 제품을 찾을 수 있고, 몰랐던 취향을 찾을 수 있다.
ALS 추천시스템
ALS는 잠재 요인 협업 필터링을 이용하는 모델이다.
협업 필터링은 사용자와 아이템간 상호작용을 확인해서 행렬의 빈공간을 추론하는 방법인데,
사용자와 아이템 사이에 잠재된 어떤 요인이 있다고 가정하고, 행렬 분해를 통해 그 요인을 찾아낼 수 있다.
(사용자-아이템 상호 작용 행렬을 두 개의 저 차원 직사각형 행렬의 곱으로 분해하여 작동)
사용자의 잠재요인과 아이템의 잠재요인을 내적해서 구매 행렬을 계산하는 방식을 사용한다.
ALS는 사용자,아이템 행렬 중 하나를 고정시키고 다른 하나의 행렬을 최적화하는 것을 반복하는 방법이다.
- ALS 선정이유
- 수렴하는 행렬을 찾을 수 있다.사용자 행렬과 아이템 행렬을 동시에 최적화하면 Non-convex하기때문에 local minima를 가지는 문제가 발생한다. 하지만 ALS 모델은 하나의 행렬을 고정하고 나머지 하나의 행렬을 최적화하는 방식을 반복하기때문에 Convex형태로서 수렴하는 행렬을 찾을 수 있다.
-
구매데이터의 불확실성을 반영할 수 있다.구매와 같은 Implicit Feedback은 선호를 나타내는 지표가 아니기때문에 데이터의 신뢰도가 부족하다. 사용자가 해당 아이템을 구매했지만 불만족하였을 수도 있고, 구매하지 않은 모든 아이템을 싫어하는 아이템으로 판단할 수도 없다. 이러한 불확실성을 ALS의 Confidence를 통해 반영할 수 있다.
- 각 군집별 추천시스템 적용
적절한 파라미터는 데이터셋마다 다르고, 데이터프레임 크기에 따라 달라질 수 있다. 또한, 최적화 시간이 매우 긴 것도 효율적이지 않다. 따라서 군집마다 각각 다른 파라미터를 적용해 최적화시켜보고, 적정한 시간 내에서 가장 좋은 퍼포먼스를 내는 최적의 군집별 파라미터를 찾았다.
그리고 각 군집별로 랜덤한 고객을 한명 선정해, 해당 고객에게 추천하는 상품 리스트를 확인해보았다.
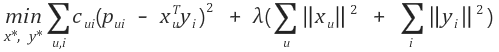
def loss_function(C, P, xTy, X, Y, r_lambda):
predict_error = np.square(P - xTy)
confidence_error = np.sum(C * predict_error)
regularization = r_lambda * (np.sum(np.square(X))+ np.sum(np.square(Y)))
total_loss = confidence_error + regularization
return np.sum(predict_error),confidence_error, regularization, total_loss
def optimizer_user(X, Y, C, P, nu, nf, r_lambda):
yT = np.transpose(Y)
for u in range(nu):
Cu = np.diag(C[u])
yT_Cu_y = np.matmul(np.matmul(yT,Cu),Y)
l = np.dot(r_lambda,np.identity(nf))
yT_Cu_pu = np.matmul(np.matmul(yT,Cu),P[u])
X[u] = np.linalg.solve(yT_Cu_y + l , yT_Cu_pu)
def optimizer_item(X, Y, C, P, ni, nf, r_lambda):
xT = np.transpose(X)
for i in range(ni):
Ci = np.diag(C[:,i])
xT_Ci_x = np.matmul(np.matmul(xT,Ci),X)
l = np.dot(r_lambda, np.identity(nf))
xT_Ci_pi = np.matmul(np.matmul(xT,Ci),P[:,i])
Y[i] = np.linalg.solve(xT_Ci_x + l,xT_Ci_pi)
predict_errors = []
confidence_errors = []
regularization_list = []
total_losses = []
for i in range(15):
if i!=0:
optimize_user(X, Y, C, P, nu, nf, r_lambda)
optimize_item(X, Y, C, P, ni, nf, r_lambda)
predict = np.matmul(X, np.transpose(Y))
predict_error, confidence_error, regularization, total_loss = loss_function(C, P, predict, X, Y, r_lambda)
predict_errors.append(predict_error)
confidence_errors.append(confidence_error)
regularization_list.append(regularization)
total_losses.append(total_loss)
print('----------------step %d----------------' % i)
print("predict error: %f" % predict_error)
print("confidence error: %f" % confidence_error)
print("regularization: %f" % regularization)
print("total loss: %f" % total_loss)
predict = np.matmul(X, np.transpose(Y))
print('final predict')
print([predict])
from matplotlib import pyplot as plt
%matplotlib inline
plt.subplots_adjust(wspace=100.0, hspace=20.0)
fig = plt.figure()
fig.set_figheight(10)
fig.set_figwidth(10)
predict_error_line = fig.add_subplot(2, 2, 1)
confidence_error_line = fig.add_subplot(2, 2, 2)
regularization_error_line = fig.add_subplot(2, 2, 3)
total_loss_line = fig.add_subplot(2, 2, 4)
predict_error_line.set_title("Predict Error")
predict_error_line.plot(predict_errors)
confidence_error_line.set_title("Confidence Error")
confidence_error_line.plot(confidence_errors)
regularization_error_line.set_title("Regularization")
regularization_error_line.plot(regularization_list)
total_loss_line.set_title("Total Loss")
total_loss_line.plot(total_losses)
plt.show()
# 고객이 산 물품
k = test_df.iloc[rcust]
k_index = np.array(k[k != 0].index)
k_index
#cust_id =고객 아이디, user_item: 예측 행렬, real:실제 행렬, N: 추천 품목 개수
def recommend(cust_id, user_item, real, N):
pred_cust = predict_df.loc[cust_id]
real_cust = real.loc[cust_id]
real_index = np.array(real_cust[real_cust != 0].index)
pred_cust_dp = pred_cust.drop(labels=real_index,axis=0)
top = np.sort(pred_cust_dp)[- N:]
print(pred_cust[pred_cust.isin(top)])
1) 첫 번째 군집 : 큰 소비 하는 규모가 작은 그룹
- 랜덤한 특정 구매자가 1년간 구매한 물품

- 위 고객이 구매하지 않은 상품 중, 10개의 추천상품

⇒ 자신을 꾸미는 것과 관련된 제품들과 여성 의류를 많이 사는 고객에게 그와 관련해서 아우터, 토트백, 향수, 페이셜 클렌저와 같이 자신을 꾸미는 것과 관련된 제품군을 주로 추천해 줌.
2) 두 번째 군집 : 주말에 장을 보는 가정
- 랜덤한 특정 구매자가 1년간 구매한 물품

- 위 고객이 구매하지 않은 상품 중, 10개의 추천상품

⇒ 식재료 구매내역이 많은 고객에게 다른 식재료를 추천해주는 것을 볼 수 있음. 간혹 여성 의류를 구매한 이력이 있는 고객에게 여성 의류 관련 품목 또한 추천함.
3) 세 번째 군집 : 필요에 의한 간헐적 소비
- 랜덤한 특정 구매자가 1년간 구매한 물품

- 위 고객이 구매하지 않은 상품 중, 10개의 추천상품

⇒ 상품권, 냉동피자, 패스트푸드만을 구매한 고객에게 관련상품뿐만 아니라 선호할 수 있는 다른 다양한 상품군을 추천해줌. 고객이 몰랐던 필요한 상품을 추천하며이용을 유도할 수 있음.
4) 네 번째 군집 : 패션관심도, 삶의 질에 대한 욕구 높음
- 랜덤한 특정 구매자가 1년간 구매한 물품

- 위 고객이 구매하지 않은 상품 중, 10개의 추천상품

⇒ 골프, 음식, 주류, 간식거리, 가전제품 등 다양한 제품군을 구매하여 여러 종류의 제품을 다양하게 추천해줌.
패션관심도와 삶의 질에 대한 욕구가 높기 때문에 추천효과가 클 것으로 보이므로 다른 고객군보다 적극적인 추천서비스를 제공.
5) 다섯 번째 군집 : 아이가 있는 3인 이상 가족의 소비 성향
- 랜덤한 특정 구매자가 1년간 구매한 물품

- 위 고객이 구매하지 않은 상품 중, 10개의 추천상품

⇒ 간편식과 육류, 식재료를 자주 구매하던 고객에게 비슷한 제품을 추천해줌.
6) 여섯 번째 군집 : 1회당 구매금액이 낮음.
- 랜덤한 특정 구매자가 1년간 구매한 물품

- 위 고객이 구매하지 않은 상품 중, 10개의 추천상품

⇒ 구매한 물품과 관련된 제품군의 다양한 제품을 추천해줌. 신중하게 제품을 고르는 고객일 가능성이 높으므로 추천서비스를 통해 충성도 높은 고객이 될 수 있음.
- 모델 성능 평가
실제 구매 행렬에서 랜덤한 고객을 선정하여 그 고객이 구매한 물품 중 20%를 사지 않았다고 가정했다.
가상 구매 행렬을 통해 추천한 10개의 물품 중, 실제로 구매했지만 구매하지 않았다고 가정한 물품의 비율을 확인했다.

랜덤 고객에 대해서 10개의 물품을 추천하는 작업을 6회 반복했다.
60개의 추천 물품 중 34개, 57%를 실제로 산 것으로 나왔다.
예상 점수가 높은 제품 목록은,
1. 실제로 선호도가 높지만 모르는 제품이거나,
2. 실제로 선호도가 높지만 현재시점에서 아직은 구매하지 않은 제품이 많을 수 있다.
(그리고 추천시스템 자체도 위와 같은 케이스를 위한 시스템이다.)
따라서 그러한 제품을 포함한 추천목록에서 실제 구매한 제품의 비율이 50% 이상이라는 것은 나쁘지 않은 성능을 보임을 의미한다.
- 추천시스템의 마케팅 효과
추천 시스템은 구매내역을 기반으로 개인에게 이미 선호가 확인된 제품과 선호할 확률이 높은 제품을 모두 추천해준다.
기존 이용내역이 많은 고객에게는 취향을 더욱 정확하게 예측해 만족스러운 추천리스트를 보여줄 수 있고
이용내역이 적은 고객에게도 좋아할 만한 제품을 추천하며 추가적인 이용을 이끌어낼 수 있다.
이를 통해, 고객은 기업이 제공하는 서비스에 대해 더 높은 만족감을 느낄 수 있으며 기업은 매출 상승과 함께 lock-in효과를 기대할 수 있다.
참고
- Ahmad Reyhan Abdillah, “Credit Card Customer Segmentation Using K-Prototype Clustering”, 2021.12.20. , https://rpubs.com/areyhan02/c3segm
RPubs - Credit Card Customer Segmentation Using K-Prototype Clustering
rpubs.com
- 아이리스, “7.54.1 R에서 실루엣 분석(Silhouette Analysis) 실시하기”, 아이리스님의 블로그, 2021. 4. 2. , https://blog.naver.com/PostView.naver?blogId=pmw9440&logNo=222296565910
7.54.1 R에서 실루엣 분석(Silhouette Analysis) 실시하기
0. 차례 1. 들어가기 2. 실루엣 계수(Sihouette Coefficient) 구하기 3. R에서 실루엣 분석실시하기 : c...
blog.naver.com
- 염창동형준킴,” 갈아먹는 추천 알고리즘 [5] ALS 구현하기”, 갈아먹는 머신러닝, 2019. 3. 29. , https://yeomko.tistory.com/8
갈아먹는 추천 알고리즘 [5] ALS 구현하기
지난 글 갈아먹는 추천 알고리즘 [1] 추천 알고리즘의 종류 갈아먹는 추천 알고리즘 [2] Collaborative Filtering 갈아먹는 추천 알고리즘 [3] Matrix Factorization 갈아먹는 추천 알고리즘 [4] Alternating Least Squa
yeomko.tistory.com
- 김현우, “협업 필터링 기반 추천시스템 –ALS”, Team EDA, 2020.12.21, 03. https://eda-ai-lab.tistory.com/529?category=736098
- [고급형]자유로운 삼각패턴(자동완성형포함) (kocw.or.kr)
- 논문에서 잘못하는 인자분석(요인분석)과 주성분.. : 네이버블로그 (naver.com)
논문에서 잘못하는 인자분석(요인분석)과 주성분 분석의 차이 이해 - 박중희
논문에서 잘못하는 인자분석(요인분석)과 주성분 분석에 대하여 01 박중희(연세대학교 인지공학연구실) 논...
blog.naver.com
[R을 활용한 논문통계] 요인분석
요인분석은 관측 가능한 여러 변수로부터 소수의 요인을 추출하여 변수 간의 관련성을 설명하는 기법으로 ...
blog.naver.com
주성분분석과 요인분석의 차이
주성분분석(Principal Component Analysis)과 요인분석(Factor Analysis)의 차이가 뭘까요? 예시로 R을 사용해서 포켓몬 능력치 데이터의 차원을 축소해보고(PCA), 씨리얼 평가의 특성을 구성하는 잠재적 요인
pizzathief.oopy.io




